Publications
(*: Equal Contribution)

Technical Report
2025
In‑Context Edit: Enabling Instructional Image Editing with In‑Context Generation in Large Scale Diffusion Transformer
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, Yi Yang
A novel approach for instructional image editing using in-context learning with large diffusion transformers, enabling precise edits through natural language instructions.

ICLR 2025 Spotlight
2025
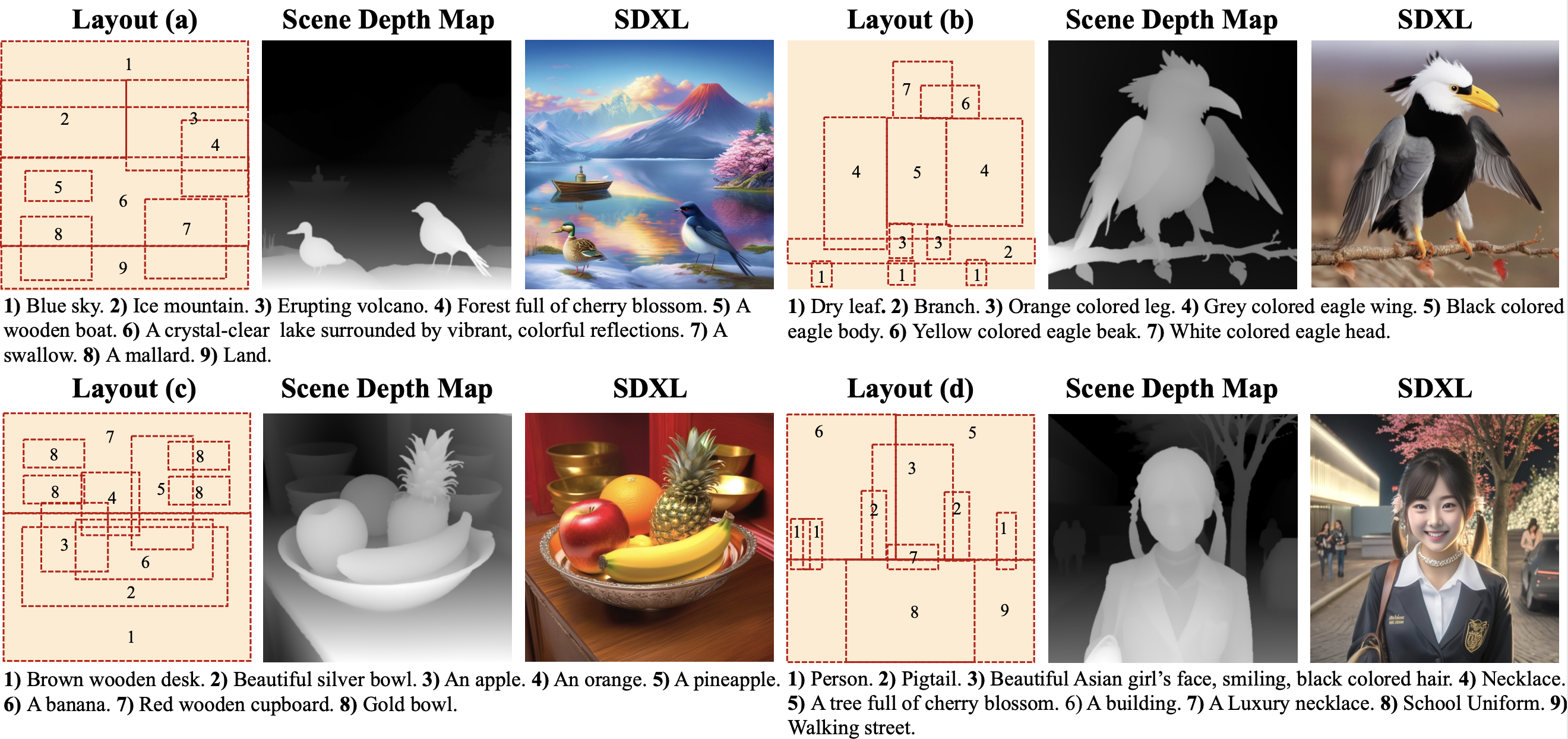
3DIS: Depth‑Driven Decoupled Instance Synthesis for Text‑to‑Image Generation
Dewei Zhou*, Ji Xie*, Zongxin Yang, Yi Yang
A depth-aware approach for generating multiple distinct instances in text-to-image synthesis, enabling better control over object placement and relationships.

Technical Report
2025
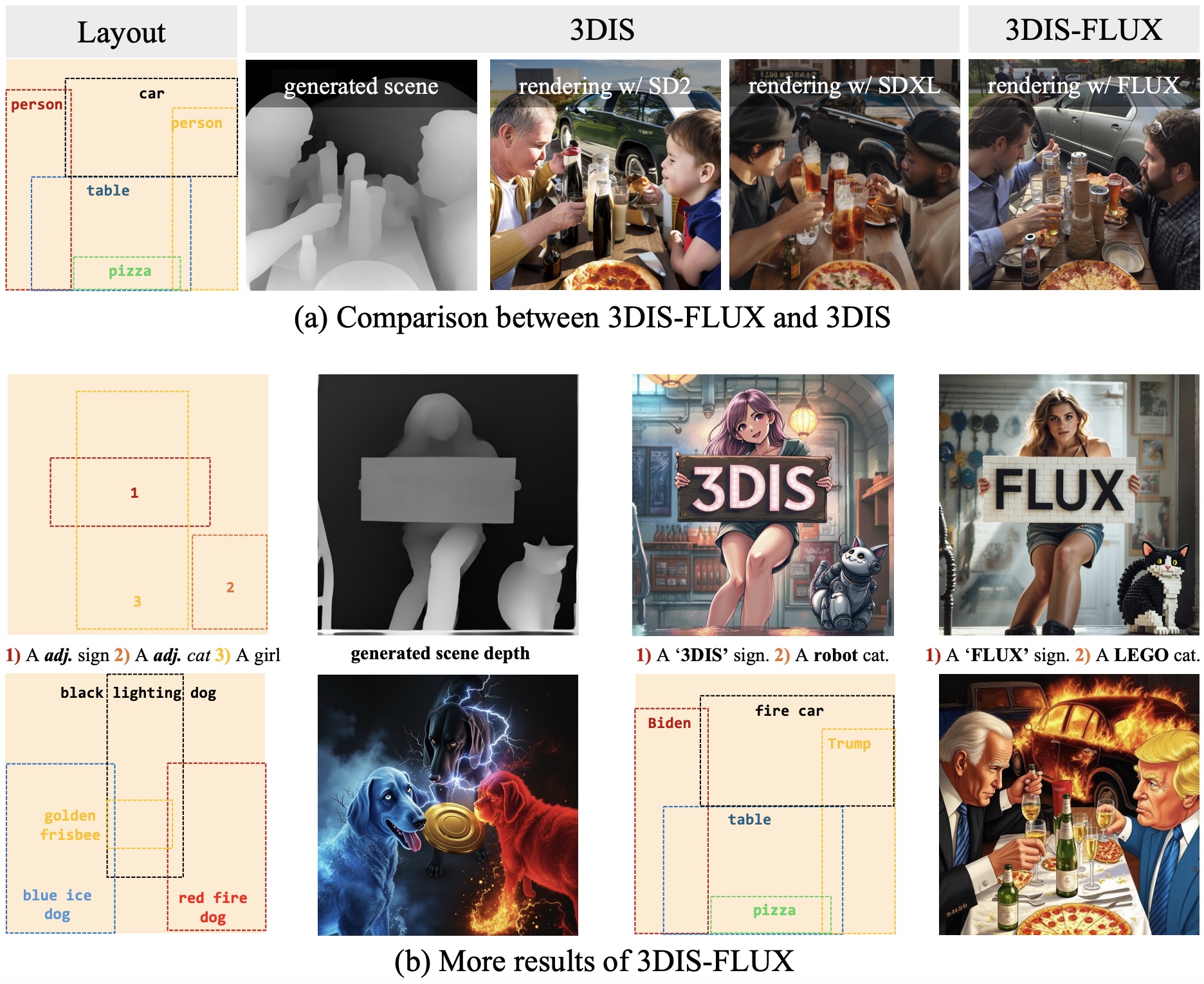
3DIS‑FLUX: Simple and Efficient Multi‑instance Generation with DiT Rendering
Dewei Zhou, Ji Xie, Zongxin Yang, Yi Yang
An extension of 3DIS focusing on efficiency and simplicity for multi-instance generation using Diffusion Transformers (DiT) with improved rendering quality.